










 免费版
免费版
- Screaming Frog SEO Spider 13
- Screaming Frog SEO Spider 13是一款十分实用的网站资源检测搜索类的软件,在我们这里主要就是可以去帮助用户们从不同的网页上来进行选择需要抓取的内容,并且这个软件还具有网页蜘蛛的一系列的功能,用户们也是可以可以让蜘蛛在网页上不断的进行搜索需要的资源。在这里也是可以设置的搜索的一个主要网页的地址,并且还可以设置一个自定义分析来进行扩展页面的功能,这样软件也是会自动在一个网站上分
- 类型:网络辅助 | 时间:2020-10-30
- 大小:429.61MB
Screaming Frog SEO Spider 13是一款十分实用的网站资源检测搜索类的软件,在我们这里主要就是可以去帮助用户们从不同的网页上来进行选择需要抓取的内容,并且这个软件还具有网页蜘蛛的一系列的功能,用户们也是可以可以让蜘蛛在网页上不断的进行搜索需要的资源。在这里也是可以设置的搜索的一个主要网页的地址,并且还可以设置一个自定义分析来进行扩展页面的功能,这样软件也是会自动在一个网站上分析几十个以及上百个网页的界面的哦。Screaming Frog SEO Spider 13这里也是可以得到自己需要的数据,甚至还可以通过这个抓取的功能的测试网页的性能,并且还可以分析一切无法响应的网页,然后再分析打开具有病毒提示的网页,另外这个软件也是完完全全的支持使用这个XPath来进行提取的数据,所以只要用户们的网站的结构来进行简练就不必担心在这里抓取的时候也有可能会出现一系列的错漏的问题,其中无论是检测这个企业的网站还是搜索的网络的资源都是非常的方便的哦!然而今天还特意为用户们带来一个补丁,这样就可以完完全全的满足用户们的需求了哦!
Screaming Frog SEO Spider 13教程
1、下载软件压缩包文件,双击打开“ScreamingFrogSEOSpider-13.0.exe",进行安装,点击Install安装向导默认设置的软件默认安装路径为C:⁄Program Files (x86)⁄Screaming Frog SEO Spider
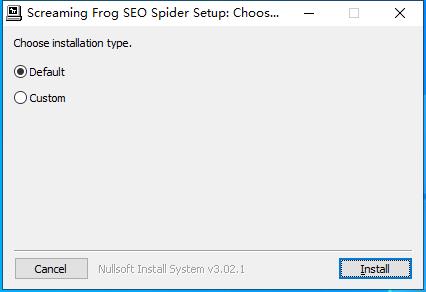
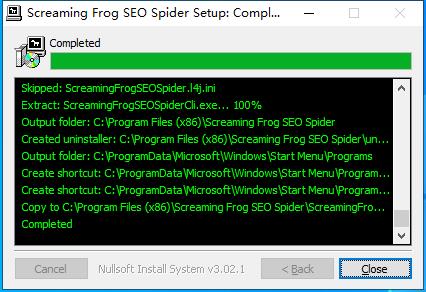
2、软件安装完成,安装向导会提示完成软件安装向导,点击Close
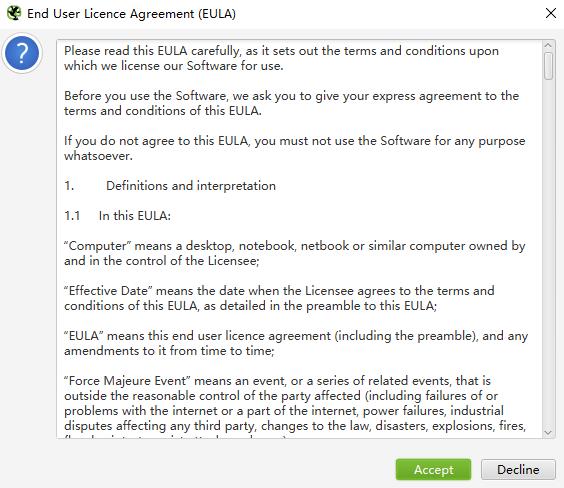
3、双击打开软件,阅读软件的许可协议,阅读完成后点击Accept
4、将Keygen_NGEN文件下的注册机双击打开
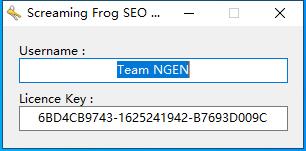
5、点击Licence下的Enter Licence,将注册机内的内容复制到软件对应位置,点击确定
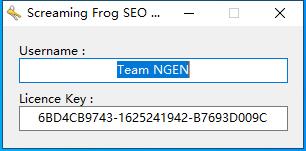
6、注册码注册成功,点击确定
7、点击Help下的About,如下图即为完成,可以放心使用软件
Screaming Frog SEO Spider 13软件功能
1、批量导出错误和源URL以修复或发送给开发人员
2、发现精确的重复网址、部分重复的网页标题、说明或标题等元素
3、使用CSS Path,XPath或regex从网页的HTML中收集任何数据
4、通过包含URL的高级配置,上次修改,优先级和更改频率
5、连接到Google AnalyticsAPI,并抓取用户数据
6、分析页面标题和元数据、审查元机器人和指令
7、允许您保存爬网,打开蜘蛛的配置选项以及自定义源代码搜索
Screaming Frog SEO Spider 13软件特色
1、找到断开的链接
立即抓取网站,找到损坏的链接(404)和服务器错误。批量导出错误和源URL以修复或发送给开发人员。
2、审计重定向
找到临时和永久的重定向,识别重定向链和循环,或者上传一个网址列表,以在网站迁移中进行审计。
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并确定在您的网站中过长,短小,缺失或重复的页面标题和元描述。
4、发现重复的内容
使用md5算法检查发现精确的重复网址、部分重复的网页标题、说明或标题等元素,并找到内容较低的网页。
5、使用XPath提取数据
使用CSS Path,XPath或regex从网页的HTML中收集任何数据。这可能包括社交元标签、额外的标题、价格、SKU或更多!
6、审查机器人和指令
查看由robots.txt、meta robots或X-Robots-Tag指令(如“noindex”或“nofollow”)以及canonicals和rel=“next”和rel=“prev”阻止的URL。
7、生成XML站点地图
快速创建XML站点地图和图像XML站点地图,通过包含URL的高级配置,上次修改,优先级和更改频率。
8、与Google Analytics集成
连接到Google AnalyticsAPI,并抓取用户数据,例如会话或跳出率和转化次数,目标,交易和着陆页的收入。
Screaming Frog SEO Spider 13使用方法
一、爬行抓取
1、常规抓取
在常规抓取模式下,Screaming Frog SEO Spider 13会抓取您输入的子域名,并将默认情况下所遇到的所有其他子域名视为外部链接(显示在“外部”标签下)。在该软件的许可版本中,您可以调整配置以选择抓取网站的所有子域。搜索引擎优化蜘蛛最常见的用途之一是在网站上发现错误,如断开的链接,重定向和服务器错误。为了更好地控制抓取,请使用您的网站的URI结构、SEO spider配置选项,例如只抓取HTML(图像、CSS、JS等)、排除功能、自定义robots.txt、包含功能或者更改搜索引擎优化蜘蛛的模式,并上传一个URI列表抓取
2、抓取一个子文件夹
SEO Spider工具默认从子文件夹路径向前抓取,因此如果您希望抓取站点上的特定子文件夹,只需输入具有文件路径的URI即可。通过直接输入到SEO Spider中,它将抓取/blog/sub目录中包含的所有URI
3、抓取网址列表
通过输入网址并点击“开始”来抓取网站,您可以切换到列表模式,粘贴或上传要抓取的特定网址列表。例如,在审计重定向时,这对于站点迁移尤其有用
二、组态
在该工具的许可版本中,您可以保存默认的爬网配置,并保存可在需要时加载的配置配置文件
1、要将当前配置保存为默认值,请选择“文件>配置>将当前配置保存为默认值”
2、要保存配置文件以便将来可以加载,请单击“文件>另存为”并调整文件名(最好是描述性的)
3、要加载配置文件,请单击“文件>加载”,然后选择您的配置文件或“文件>加载最近”以从最近的列表中进行选择
4、要重置为原始Screaming Frog SEO Spider 13版默认配置,请选择“文件>配置>清除默认配置”
三、出口
顶部窗口部分的导出功能在顶部窗口中与您当前的视野一起工作。因此,如果您使用过滤器并单击“导出”,则只会导出过滤选项中包含的数据
有三种主要的数据导出方法:
1、导出顶层窗口数据:只需点击左上角的“导出”按钮,即可从顶层窗口选项卡导出数据
2、导出较低的窗口数据(URL信息、链接、输出链接、图像信息):要导出这些数据,只需在顶部窗口中右键单击要导出数据的URL,然后单击“导出”下的“URL信息”、“链接”、“出链接”或“图片信息”
3、批量导出:位于顶层菜单下,允许批量导出数据。您可以通过“all in links”选项导出抓取中找到的链接的所有实例,也可以将所有链接全部导出到具有特定状态代码(如2XX,3XX,4XX或5XX响应)的URL。例如,选择“链接中的客户端错误4XX”选项将导出全部链接到所有错误页面(例如404错误页面)。您还可以导出所有图像替代文字,所有图像缺少替代文字和所有锚点文字
以上就是11ba小编为大家带来的Screaming Frog SEO Spider 13的详细介绍,喜欢就收藏一下吧!说不定会找到你要的惊喜╰(*°▽°*)╯~
相关教程
更多 - 探索ER的奥秘:深入了解与发现 01.23
- 魏哲鸣结婚时间 01.23
- 注册苹果ID时遇阻,提示需联系iTunes支持完成交易怎么办? 01.08
- 如何使用163网盘? 01.02
- 成衣店:一站式打造时尚造型的秘密基地 12.05
猜你喜欢








相关专题
网络辅助软件大全








大力推荐
更多 -

- yaanp
- 网络辅助 | 183.31MB
- 2021-09-10 | yaanp专业版是一款很好用的工具类型的软件,如果有需要网络的分析处理相关需求的朋友们可以关注一下yaanp免费版的下载,11ba小编为您提供!在技术层面上,yaanp这款软件拥有强大的专业能力,通过计算机算法和最新的图形引擎技术辅助,保证你的工作效率和用户体验,能帮助你更加专业的完成网络分析的操作,喜欢这款软件的小伙伴们快来11ba下载站下载体验吧!
-

- Wireshark(网络抓包工具)
- 网络辅助 | 52.89MB
- 2021-08-24 | Wireshark是一款可以实时监测电脑的网络通讯情况的管理工具,可以检测抓取的网络通信数据快照文件。 Wireshark软件这些数据可以通过图形界面进行浏览,可以查看网络通信数据包中各层的详细内容。喜欢的用户快来看看吧!
-

- sockscap64
- 网络辅助 | 16.67MB
- 2021-08-24 | sockscap64是一款功能全面的免费开源网络辅助工具,支持本地域名解析,先本地再远程代理解析,新手用起来也是十分的方便,sockscap64软件使用教程也是十分的详细,让电脑的网页访问速度变得很快,有需要的用户快来下载使用吧!
-

- pycharm2020激活码
- 网络辅助 | 11.6MB
- 2021-08-24 | pycharm2020激活码可以完美激活pycharm2020这款软件工具,pycharm2020是一款为学习python人工智能的新手小白打造的编程工具,提供了完善的框架支持,pycharm2020激活码获取途径还是很多的,下面就是11ba小编为大家整理的pycharm2020激活码详细介绍,快来看看吧!
-

- 超级抢票机
- 网络辅助 | 19.21MB
- 2021-08-24 | 超级抢票机是一款十分实用的在线抢票工具,帮助用户可以在节假日抢票可以快人一步,超级抢票机破解版抢票速度秒杀浏览器式抢票软件,毫秒级自动识别验证码,让用户在节假日能够可以容易的同家人团聚,快来看看吧!
-

- Fiddler(网络抓包工具)5.0.20194.41348绿色汉化版
- 网络辅助 | 12.11MB
- 2021-08-24 | Fiddler5.0.20194.41348绿色汉化版是一款十分好用的网络抓包工具,操作更简单,灵活性好,支持大部分http调试任务,Fiddler使用教程十分的详细,新手用来抓包也是十分的得心应手,有需要的用户快来看看吧!
-

- 哆点
- 网络辅助 | 9MB
- 2021-04-06 | 哆点是广州热点有限公司开发的一款拨号上网软件,软件会自动识别校园网络以及多种无限网络场景让你一键连接,并且支持多个账号来回自由切换,非常方便,软件目前覆盖城市有许多,因为操作简单迅速受到了全国各大高校学生的喜爱,让用户们再也不用担心网络卡顿以及流量不够的情况了
-

- 野兔谷日志宝
- 网络辅助 | 38.59MB
- 2021-04-06 | 野兔谷日志宝是一款提取和分析网站日志文件的免费工具。支持Apache,Nginx,Tengine,IIS的网站日志文件。您可以建立不同的分组,然后导入日志进行分析,分析之前筛选条件,以便于找到目标日志记录,比如IP、时间段、访问路径关键字、来路关键字、User
-

- 网络维护工具
- 网络辅助 | 4.87MB
- 2021-03-17 | 网络维护工具是一款功能强大的网络维护软件,该软件界面整洁,操作简单,可以让用户更好的使用网络。整合了网络维护工具四件套,包含了网址检测,更改IP、网关、子网掩码和DNS,重置网络,检测网络信息和状态多个功能,由易语言编写,直接开启程序即可快速运行对应的检测功能
-

- 京东抢茅台
- 网络辅助 | 54.96MB
- 2021-03-11 | 京东抢茅台是一款针对茅台抢购所制作的辅助工具。由强大的网友通过python语言编写而成,抢购茅台已成为了一股风潮,但很多用户手速不够快,天猫超市的基本都是黄牛软件在抢购,点击进去一两秒后就没了,相比较来说还是京东比较好抢一些,那么如何提高抢购成功率呢?不妨试试
-

- PingPlotter Pro
- 网络辅助 | 23.92MB
- 2021-03-09 | PingPlotterPro是一款非常强大实用且专业的网络监测软件。这款软件的功能非常的强大且实用,它可跨数百个目标可视化网络性能数据,帮助用户监测和排查各种网络问题,并及时就解决。它会不断检测网络、服务站等活跃传入和传出的数据包,以此保证自己连接的没有任何的
-

- Steamcommunity 302(steam连接修复工具)
- 网络辅助 | 16.67MB
- 2021-03-04 | Steamcommunity302是一款专门为steam平台打造的一款实用修复工具。它能够解决大部分情况下连接不上steam的问题,让你能够轻松进入steam社区,浏览自己想要看到的页面,畅想极速体验。这个软件打开后,只需要点击启动服务就能够解决问题,它会修改
-

- Complete Internet Repair
- 网络辅助 | 6.69MB
- 2021-03-04 | CompleteInternetRepair是一款用于网络故障问题修复的工具,无论是您的TCP/IP设置错误还是Winsock、DNS、IE浏览器设置错误等等,本软件都可以很好的为您修复。我们经常会遇到网络宽带线路正常的情况下,无法上网,造成这类问题出现的原来
-

- ADSL超频奇兵
- 网络辅助 | 6.78MB
- 2021-03-04 | ADSL超频奇兵是一款非常实用的ADSL加速软件,永久免费使用。该软件可以通过修改PC系统注册表中原来专为低速接入而设置的TCP/IP默认参数,以适应PPPOE方式的ADSL接入,实测可提高一倍左右的下载速度并解决了ADSL浏览网页停顿、速度减慢的问题。它界面
-

- 易大师网络工具箱
- 网络辅助 | 8.87MB
- 2021-02-26 | 易大师网络工具箱是一款功能丰富的网络工具合集软件,软件汇集了多种实用的网络工具,可以帮助用户进行网络的各种操作,可以轻松解决各种网络的问题。支持本机信息、本机网络信息、网络连接等网络信息情况,让你很方便地查看电脑的网络、硬件信息。支持路由跟踪技术,只需输入IP









